
Introduction: Why Enterprise DevOps Failure Rates Remain High in 2026
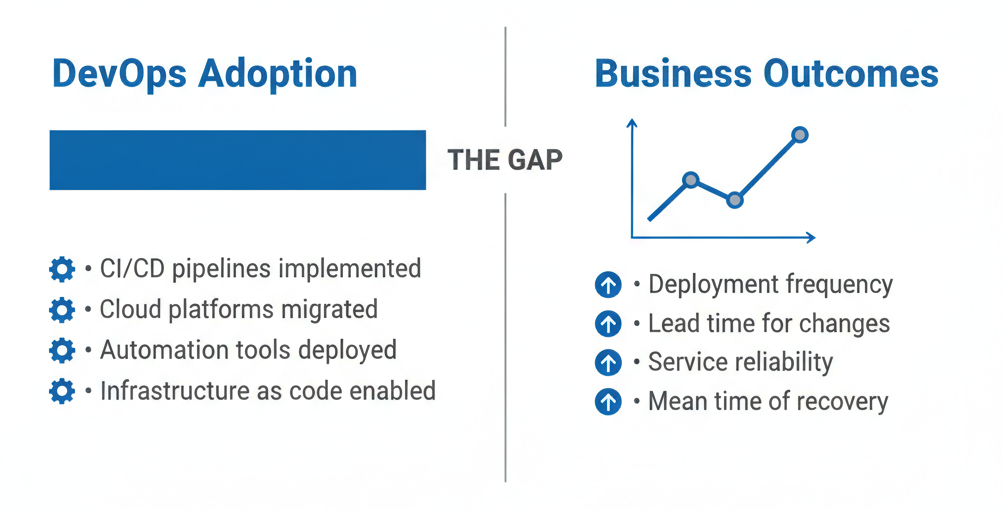
DevOps adoption across large enterprises is no longer experimental. Multiple industry reports show that over 80 percent of Fortune 500 organizations have initiated DevOps programs, often supported by significant investments in cloud platforms, CI CD tooling, and automation frameworks. Despite this widespread adoption, fewer than 40 percent report sustained, enterprise-wide improvements in core delivery metrics such as deployment frequency, lead time for changes, service availability, and mean time to recovery.
This gap between adoption and outcomes explains why DevOps fails in big companies at such a high rate. This pattern is a recurring signal of why DevOps fails in big companies despite years of investment. Enterprises frequently measure success by surface indicators like tool rollout completion, number of pipelines created, or cloud migration milestones. However, these indicators rarely translate into improved customer experience, faster innovation, or reduced operational risk.

In reality, enterprise DevOps challenges are structural. Without rethinking governance models, funding flows, organizational design, legacy architecture, and leadership incentives, DevOps initiatives deliver isolated wins rather than systemic change. Teams work harder, not better, and the organization sees diminishing returns on DevOps investments.
DevOps transformation failures are rarely caused by a lack of engineering capability or access to modern tools. They occur because enterprise operating models were never designed to support continuous delivery at scale.
DevOps Was Built for Speed While Enterprises Are Built for Control
DevOps practices originated in environments optimized for fast feedback loops, experimentation, and decentralized decision-making. Startups and digital-native companies prioritize rapid learning and adaptability, accepting short-term risk in exchange for long-term velocity.
Large enterprises, especially those in regulated industries such as banking, healthcare, insurance, and telecommunications, evolved around control, predictability, and auditability. Their operating models emphasize risk prevention, standardized processes, and centralized oversight.
This structural mismatch is one of the most common reasons DevOps fails in big companies. Organizations demand faster releases while retaining governance frameworks designed for quarterly or annual release cycles. Teams are expected to move faster without being empowered to redesign how work flows through approvals, reviews, and handoffs.
The outcome is familiar. CI CD pipelines exist, infrastructure is automated, but releases still queue behind approval meetings. Lead times remain high, engineers experience frustration, and leadership questions why DevOps has not delivered measurable business value. Until governance models evolve, DevOps fails in big companies regardless of tooling maturity.
Enterprise Governance Models That Block Continuous Delivery
Traditional enterprise governance relies heavily on manual approvals, centralized change advisory boards, and static risk assessments performed before deployment. Industry benchmarks consistently show that organizations with multiple manual approval layers experience lead times three to five times longer than those using automated, policy-driven controls.
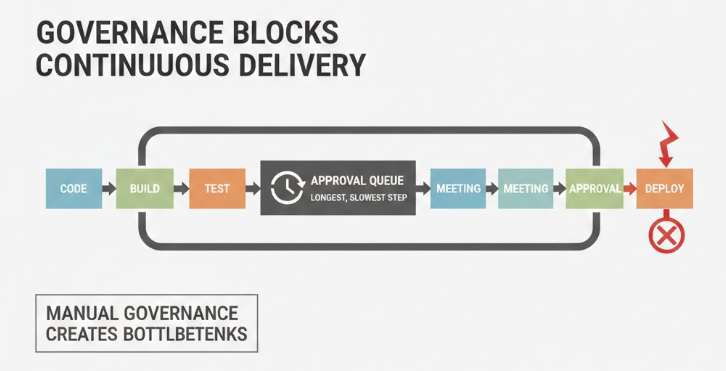
Manual governance scales poorly. As deployment frequency increases, approval queues grow, meetings multiply, and exceptions become routine. This creates a false sense of safety while actually increasing operational risk through rushed approvals and workarounds. This is a classic enterprise pattern where DevOps fails in big companies due to approval bottlenecks.
Enterprise case study: Global bank
A Tier 1 global bank implemented CI CD pipelines across its digital banking platforms, achieving high levels of automation for testing and deployment. Despite this, releases were still delayed by weekly change advisory board meetings involving dozens of stakeholders.
By replacing manual approvals with automated compliance checks, enforced test coverage thresholds, and continuous post-deployment monitoring, the bank reduced lead time by more than 50 percent. Importantly, regulatory findings declined, and incident rates remained stable, demonstrating that automation improved both speed and control.
Risk Management Is Not the Same as Risk Avoidance
Many enterprises equate stability with minimizing the number of changes deployed to production. This mindset assumes that fewer releases reduce failure probability. High-performing DevOps organizations take a fundamentally different approach.
They reduce risk by deploying smaller changes more frequently, making failures easier to detect, diagnose, and reverse. Industry data consistently shows that smaller batch sizes correlate with lower change failure rates and faster recovery times.
DevOps fails in big companies when leadership focuses on preventing change rather than managing it. Long-lived branches, large release batches, and infrequent deployments increase blast radius and recovery time, amplifying risk instead of reducing it.
Tool-First DevOps Adoption Creates the Illusion of Progress
One of the most persistent enterprise DevOps challenges is treating DevOps as a tooling initiative. Organizations invest heavily in CI CD platforms, container orchestration systems, cloud infrastructure, and observability stacks expecting transformation to follow automatically.
While tooling improves automation metrics such as pipeline execution time or test coverage, studies show little correlation between tool adoption alone and improvements in time to market, customer satisfaction, or operational resilience.
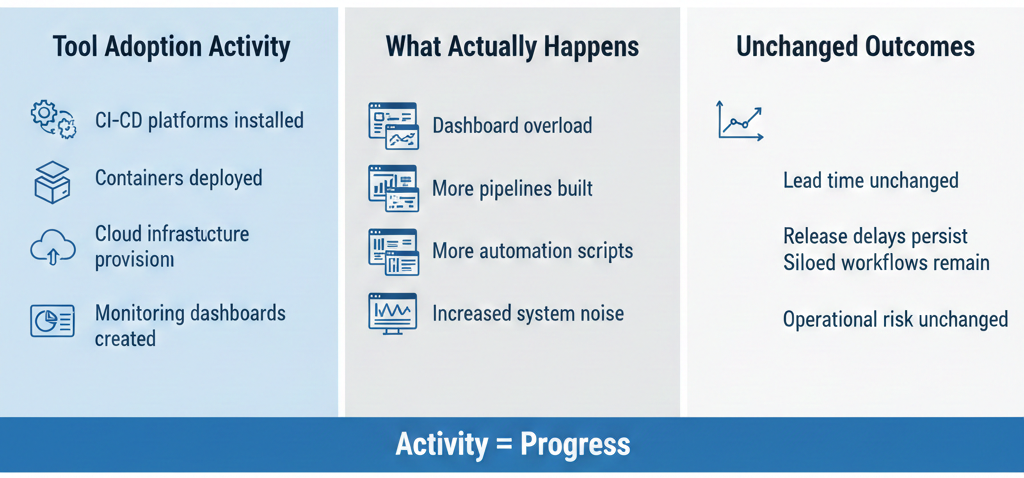
Enterprises often mistake activity for progress. Dashboards fill with metrics, pipelines multiply, but underlying delivery constraints remain unchanged. This disconnect fuels skepticism about DevOps at the executive level. This illusion of progress explains why DevOps fails in big companies that prioritize tools over operating models. In these environments, DevOps fails in big companies quietly, without obvious technical breakdowns.
Standardization Without Organizational Alignment Slows Delivery
To control cost and reduce complexity, enterprises often mandate standardized DevOps tooling across teams. Standardization can be valuable, but without alignment around outcomes and value streams, it becomes restrictive.
Teams forced into standardized tools without shared ownership models or delivery goals experience reduced autonomy and slower feedback loops.
Enterprise case study: Global retailer
A multinational retailer standardized CI CD tooling across hundreds of teams worldwide. Adoption metrics appeared successful, but delivery performance varied dramatically. Teams aligned around end-to-end product ownership consistently outperformed functionally organized teams, proving that organizational alignment mattered more than tool uniformity.
Automating Inefficiency at Enterprise Scale
Automation amplifies existing workflows. Enterprises that automate fragmented, approval-heavy, or poorly designed processes simply scale inefficiency.
This pattern explains many DevOps transformation failures. Automation accelerates bottlenecks, increases exception handling, and hides structural problems behind scripts and dashboards.
Without simplifying workflows and reducing handoffs, automation delivers diminishing returns. At scale, this pattern reinforces why DevOps fails in big companies despite heavy automation investment.
Organizational Silos Undermine DevOps at Scale
Large enterprises are traditionally organized around specialized functions such as development, operations, security, quality assurance, and compliance. While specialization enables expertise, it also creates handoffs, delays, and conflicting incentives.
Research consistently shows that organizations with high handoff rates experience longer lead times, higher failure rates, and slower recovery. DevOps fails in big companies when accountability is fragmented and no team owns outcomes end to end.
The Hidden Cost of Escalations and Handoffs
Escalation-driven operating models replace ownership with coordination. Incidents move between teams instead of being resolved collaboratively, increasing resolution time and reducing learning.
Enterprise case study: Telecom provider
A global telecom organization reduced incident resolution time by more than 40 percent after reorganizing teams around services rather than functions. Teams gained end-to-end ownership, reducing escalation chains and improving both reliability and deployment confidence.
Security and Compliance as Late-Stage Gates
In many enterprises, security and compliance remain external checkpoints applied late in the delivery lifecycle. This leads to rework, emergency approvals, and rushed fixes near release deadlines.
Organizations that embed security controls directly into delivery pipelines report fewer vulnerabilities, faster audits, and higher release confidence. Security becomes a continuous capability rather than a blocking function. This late-stage gating model is another reason DevOps fails in big companies operating in regulated environments.
Legacy Systems and Architectural Constraints Limit DevOps Impact
Most large enterprises operate complex portfolios of legacy systems that were not designed for continuous delivery. Monolithic architectures, shared databases, and tightly coupled integrations limit independent deployment and experimentation.
DevOps fails in big companies when delivery practices are modernized without addressing architectural constraints. Teams adopt modern workflows but remain bound by legacy dependencies.
DevOps Without Architectural Evolution Fails
High-performing enterprises align DevOps initiatives with incremental architectural evolution rather than large-scale rewrites. Techniques such as API isolation, strangler patterns, and service decomposition enable progress without destabilizing core systems.
Enterprise case study: Global financial institution
A large financial organization enabled DevOps by isolating customer-facing services behind APIs while maintaining stable core transaction systems. This approach allowed frequent releases and rapid experimentation without compromising critical operations.
Leadership Misalignment and Transformation Theater
Executive sponsorship for DevOps is often highly visible but strategically shallow. Leaders approve tooling budgets, attend kickoff meetings, and publicly endorse DevOps, yet continue to optimize the organization for utilization, cost containment, and short-term predictability. This creates an inherent contradiction. Teams are asked to increase deployment speed and experimentation while being measured and rewarded under models designed to minimize change.
When DevOps is framed primarily as an engineering initiative, its systemic nature is misunderstood. Decisions about funding, staffing, governance, and risk tolerance remain centralized and slow, even as teams are encouraged to move faster. This disconnect prevents DevOps practices from translating into measurable business outcomes.
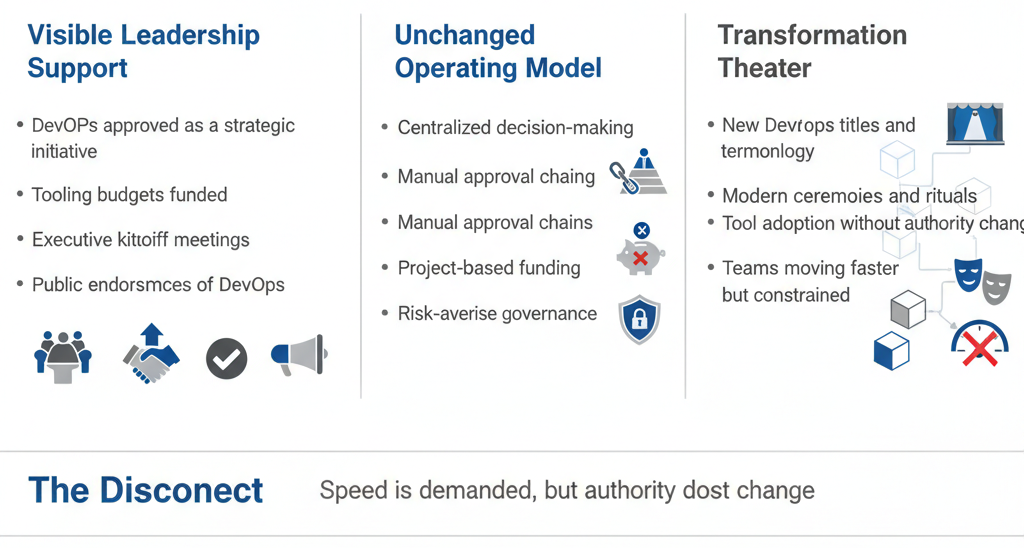
The result is transformation theater. Teams adopt DevOps terminology, introduce new tools, rename roles, and run modern ceremonies, but the underlying decision-making structures remain unchanged. Approval chains persist, incentives remain misaligned, and authority is not redistributed. Over time, engineers recognize the gap between stated goals and lived reality, and initial enthusiasm gives way to skepticism and disengagement.
True DevOps leadership requires more than endorsement. It requires leaders to change how trade-offs are made, how risk is evaluated, and how success is defined across the organization. This gap between intent and authority is a major reason DevOps fails in big companies even with executive support.
DevOps Must Be a Permanent Operating Model
DevOps transformations fail when they are treated as temporary programs with defined start and end dates. Time-bound initiatives encourage surface-level adoption focused on visible milestones rather than lasting behavioral change. Once the program concludes, momentum fades, funding is redirected, and teams revert to legacy practices.
Enterprises that succeed embed DevOps principles into their operating model. Governance frameworks are redesigned to support continuous delivery. Budgeting processes shift from annual project funding to persistent product and platform investment. Performance management evolves to reward learning, reliability, and customer impact rather than short-term output.
In these organizations, DevOps is not something that teams implement. It becomes how the enterprise plans, builds, delivers, and operates systems every day. This permanence creates consistency, reinforces accountability, and allows improvements to compound over time. Without permanence, DevOps fails in big companies once transformation programs end.
Misaligned Metrics and Incentives Kill DevOps Momentum
Metrics define what an organization values. Enterprises that reward utilization, ticket throughput, or individual output unintentionally discourage experimentation, collaboration, and shared ownership. Teams optimize for local efficiency at the expense of system-wide flow.
When metrics reward local efficiency over flow, DevOps fails in big companies even with mature tooling. High-performing DevOps organizations measure outcomes instead of activity. Metrics such as lead time, deployment frequency, change failure rate, and recovery speed provide a clearer picture of delivery health. When combined with customer satisfaction and reliability indicators, these metrics align technical performance with business value.
Incentive structures must reinforce these metrics. When leaders reward teams for improving flow efficiency and reliability, behaviors change. Collaboration increases, handoffs decrease, and teams invest in automation and resilience.
Metrics shape behavior at scale. When enterprises change what they measure and reward, the system adapts. This shift is often the difference between stalled DevOps adoption and sustained enterprise-wide success.
Proven Fixes That Actually Work in Large Enterprises
Enterprises that succeed with DevOps do not chase isolated improvements or short-term wins. Instead, they focus on system-level change that reshapes how work flows across the organization. This includes redesigning governance to balance autonomy with guardrails, modernizing funding models, and aligning organizational structures with value delivery rather than functional efficiency.
High-performing enterprises recognize that DevOps is not a technical framework but an operating philosophy. They invest in long-term capability building instead of one-time transformations. Data shows that organizations taking this approach experience compounding benefits over time, including higher service reliability, faster recovery from incidents, improved employee engagement, and lower operational risk.
These enterprises also accept that DevOps maturity is uneven and non-linear. Rather than forcing uniform adoption, they enable teams to progress at different speeds while maintaining shared standards and outcomes. These fixes directly address the structural reasons DevOps fails in big companies year after year.
Platform Engineering Enables Safe Speed at Scale
As enterprises scale DevOps, cognitive load becomes a limiting factor. Product teams are expected to manage infrastructure, security, compliance, observability, and delivery pipelines in addition to building features. Without support, this complexity slows teams down and increases error rates.
Platform engineering addresses this challenge by providing internal platforms that abstract complexity and enforce standards through self-service capabilities. Secure deployment templates, pre-approved infrastructure patterns, identity management, and built-in observability allow teams to focus on delivering value instead of managing plumbing.
Organizations that invest in platform engineering report measurable gains. Reduced onboarding time, fewer security incidents, and more consistent delivery performance across teams are common outcomes. Platform teams act as force multipliers, improving both speed and safety simultaneously.
Enterprise Case Study: SaaS at Global Scale
A global SaaS organization operating across multiple regions struggled with inconsistent delivery performance and long onboarding times for new engineers. Each team maintained its own deployment processes, security configurations, and tooling conventions, leading to fragmentation and operational risk.
By introducing a centralized internal platform, the organization standardized deployment pipelines, security controls, and monitoring practices while preserving team autonomy. Developers could launch new services using pre-approved templates that met compliance and reliability requirements by default.
The results were immediate and sustained. Developer onboarding time dropped by more than 60 percent, deployment frequency increased across teams, and incident rates declined. Most importantly, the platform created a shared foundation that allowed DevOps practices to scale without increasing risk or complexity.
Value Stream Alignment and Team Topologies
One of the most impactful changes enterprises can make is reorganizing teams around value streams rather than technical functions. When teams own outcomes end to end, handoffs decrease, feedback loops tighten, and accountability becomes clearer.
Modern team topology models distinguish between product teams, platform teams, and enabling teams, each with defined responsibilities and interaction modes. This clarity reduces friction and prevents overlapping ownership, which is a common source of delay in large organizations.
Enterprises that adopt value stream alignment consistently outperform peers on delivery speed and reliability. Teams understand how their work contributes to customer outcomes, and leadership gains clearer visibility into bottlenecks and dependencies across the organization.
Governance Through Automated Controls
Traditional governance relies on human checkpoints that do not scale with deployment frequency. Automated controls embedded directly into delivery pipelines offer a more effective alternative.
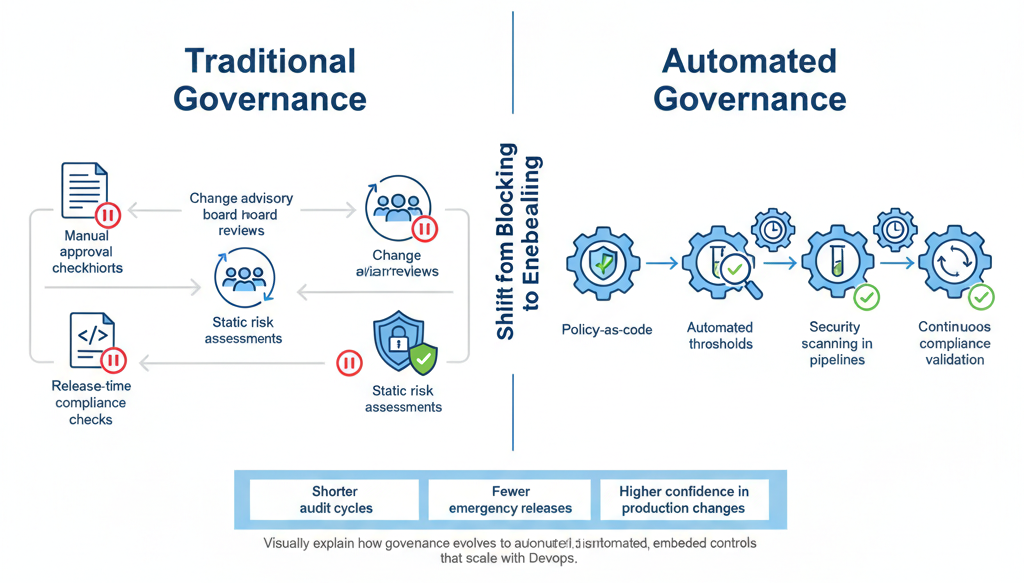
Policy-as-code, automated testing thresholds, security scanning, and compliance validation ensure that standards are enforced consistently without slowing teams down. These controls generate auditable evidence continuously, reducing the need for manual reviews and last-minute approvals.
Enterprises adopting automated governance report shorter audit cycles, fewer emergency releases, and higher confidence in production changes. Governance shifts from a blocking function to an enabling capability that supports safe, continuous delivery.
Why These Fixes Succeed Where Others Fail
The common thread across successful enterprise DevOps transformations is alignment. Governance, architecture, organizational design, metrics, and leadership incentives reinforce each other instead of working at cross purposes.
Rather than copying startup practices, these organizations redesign their systems to support continuous change at scale. They manage risk through automation, clarity, and ownership instead of restriction. Over time, DevOps becomes invisible because it is simply how the enterprise operates.
This is why these fixes endure. They address root causes rather than symptoms, creating resilience and adaptability that persist long after the initial transformation effort. This alignment is precisely what prevents DevOps fails in big companies from repeating across transformation cycles.
Frequently Asked Questions
Why does DevOps fail more often in large enterprises than in smaller organizations
DevOps fails in enterprises due to scale, governance complexity, legacy systems, and siloed organizational structures that smaller organizations do not face.
Can DevOps succeed in highly regulated industries
Yes. Regulated organizations succeed by embedding compliance into delivery pipelines through automation rather than manual approvals.
Are DevOps tools enough to fix enterprise delivery problems
No. Tools enable automation, but organizational design, leadership alignment, governance, and architecture determine success.
How long does an enterprise DevOps transformation take
Meaningful enterprise DevOps transformations typically take two to four years depending on maturity and technical constraints.
Conclusion: DevOps Success Requires Structural, Not Cosmetic, Change
DevOps fails in big companies when implemented as a surface-level initiative rather than a systemic transformation. Large organizations must address governance models, organizational silos, leadership incentives, funding structures, and architectural constraints together. Successful enterprise DevOps is not defined by speed alone. It is defined by the ability to change safely, predictably, and continuously at scale. Organizations that succeed redesign how risk is managed, how teams are structured, and how value flows across the enterprise.
If your organization has invested in DevOps but continues to struggle with slow delivery, high failure rates, or stalled transformation, the root cause is almost always structural rather than technical. Understanding why DevOps fails in your enterprise is the first step toward implementing fixes that actually work at scale and create long-term operational advantage. Recognizing why DevOps fails in big companies is the first step toward building delivery systems that scale safely.
Comments