
DevOps has evolved from a niche engineering philosophy into a core business enabler for modern organizations. Today, DevOps Case Studies provide practical insight into how companies scale software delivery while maintaining reliability, security, and operational control. These DevOps Case Studies move beyond theory to show how real organizations align development, operations, and business teams to deliver software faster and more safely at scale.
At its core, DevOps represents a shift in how organizations think about software delivery. Rather than treating development and operations as separate functions, DevOps encourages shared ownership, continuous feedback, and automation across the entire lifecycle. This alignment enables enterprises to respond faster to market changes, reduce failure rates, and improve customer experience without sacrificing governance or stability. For large organizations with distributed teams and legacy infrastructure, this shift is not incremental; it is transformational.

Enterprise DevOps case studies are particularly valuable because they move the conversation beyond theory and aspirational frameworks. They demonstrate how real organizations with millions of customers, global footprints, strict compliance requirements, and deeply embedded legacy systems have successfully implemented DevOps at scale. These examples make it clear that DevOps success is not driven solely by adopting cloud platforms or deploying new tools. Instead, sustainable results come from deliberate cultural change, disciplined investment in automation, and long-term platform thinking that prioritizes consistency, reuse, and developer enablement.
The case studies that follow examine how Netflix, Spotify, Target, Capital One, and Etsy approached DevOps transformation through a combination of external consulting, internal enablement programs, and strong engineering leadership. Each organization faced different constraints and priorities, yet all used DevOps principles to improve system resilience, accelerate software delivery, and build organizational confidence. Together, these stories offer practical lessons for enterprises seeking sustainable digital transformation. They highlight that DevOps maturity is not achieved through short-term optimization or isolated initiatives, but through consistent leadership commitment, investment in people and platforms, and a willingness to rethink how technology and business outcomes are connected. These DevOps Case Studies focus on real-world enterprise environments where scale, reliability, and organizational complexity shape every engineering decision.
Netflix and Engineering for Resilience at Global Scale Devops Case Studies
Among modern DevOps Case Studies, Netflix stands out for its focus on resilience and automation at global scale. Netflix is widely regarded as one of the earliest and most influential adopters of DevOps practices at enterprise scale. Its transformation did not begin as a technology experiment, but as a business necessity. When Netflix transitioned from a DVD rental service to a global streaming platform, software availability became inseparable from the customer experience. Unlike traditional enterprises where outages might be absorbed internally, any disruption at Netflix was immediately visible to millions of users worldwide. Reliability, therefore, was no longer a technical metric managed by IT teams; it became a core business imperative tied directly to revenue, brand trust, and customer retention.
As Netflix expanded globally, the company encountered the inherent complexity of distributed systems. Instead of attempting to prevent every possible failure through rigid controls, Netflix made a deliberate and unconventional decision to assume that failures would occur. This acceptance fundamentally shaped its DevOps philosophy. The company recognized that modern cloud-native systems are too complex to be fully predicted, making resilience more valuable than perfection. This mindset led to the development of chaos engineering practices, most notably Chaos Monkey, a tool designed to deliberately disrupt production environments by randomly terminating instances. By injecting failure intentionally, Netflix forced engineering teams to design services that could tolerate and recover from unexpected conditions without human intervention.
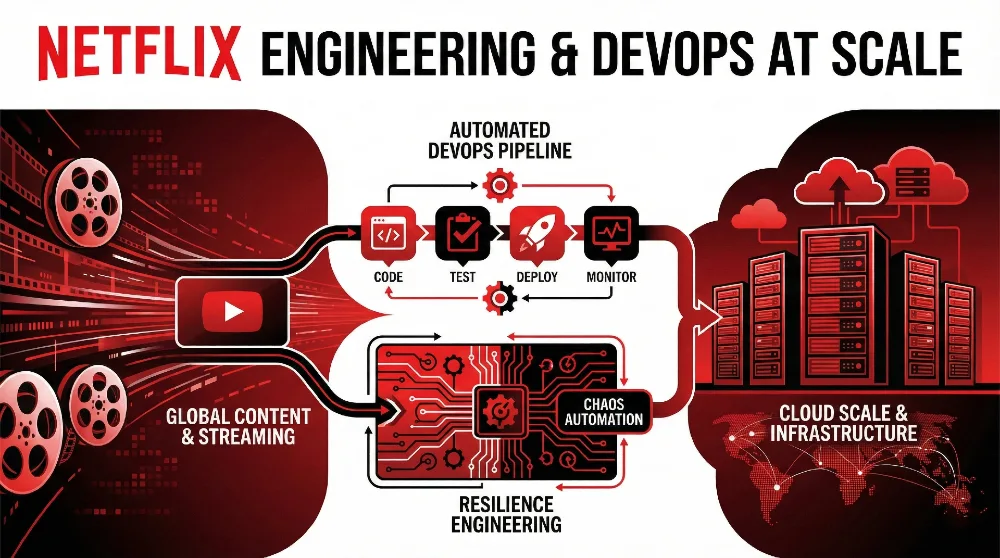
These practices created a powerful feedback loop. Engineers learned quickly where systems were fragile, dependencies were poorly understood, or recovery mechanisms were inadequate. Over time, resilience became embedded into application design rather than added as an afterthought. This approach shifted operational responsibility earlier into the development lifecycle, aligning strongly with DevOps principles of shared ownership and continuous learning.
In parallel with its resilience strategy, Netflix invested heavily in automated continuous delivery. Manual deployment processes could not support the company’s rapid innovation pace or its microservices-based architecture. To address this challenge, Netflix developed Spinnaker, a centralized deployment platform designed to standardize and automate application releases across thousands of services. Spinnaker enabled sophisticated deployment strategies such as canary releases, automated rollbacks, and traffic shaping, significantly reducing the risk associated with frequent deployments. By abstracting deployment complexity behind a shared platform, Netflix empowered engineering teams to release code independently while maintaining consistency and operational safety.
Culturally, Netflix reinforced DevOps by redefining accountability. Engineers were expected to own their services end to end, from development through production operations. Monitoring, alerting, and incident response became essential components of the engineering role rather than responsibilities delegated to separate operations teams. This model reduced handoffs, improved incident response times, and strengthened feedback between system behavior and design decisions. Transparency was encouraged through shared metrics and post-incident reviews focused on systemic improvement rather than individual fault.
Netflix’s DevOps transformation illustrates that resilience at scale is not achieved through centralized control or restrictive processes. Instead, it emerges from automation, platform investment, and a culture that treats failure as a source of insight. By designing systems that anticipate disruption and recover quickly, Netflix created an environment where teams could innovate continuously without compromising service reliability. This balance between speed and stability remains a defining characteristic of Netflix’s engineering organization and a benchmark for DevOps maturity across industries.
Spotify and Scaling DevOps Through Developer Experience
The following DevOps Case Studies also highlight how organizational design and developer experience influence long-term scalability.
Spotify is frequently referenced in DevOps Case Studies for its platform-driven approach to developer experience. Spotify approached DevOps transformation from a fundamentally different perspective than many technology-driven organizations. Rather than centering its strategy on infrastructure reliability alone, Spotify focused on organizational scalability and developer effectiveness as the company experienced rapid global growth. As Spotify expanded its product offerings and engineering workforce, the complexity of its software ecosystem increased dramatically
Hundreds of independently developed services, a wide variety of programming languages, and autonomous engineering teams created an environment where understanding how systems fit together became increasingly difficult. Over time, this complexity began to slow development, increase onboarding time for new engineers, and introduce operational risk that traditional DevOps tooling alone could not resolve.
Spotify recognized early that DevOps success at scale depends as much on human factors as it does on technology. As systems grow, the cognitive load placed on engineers can become a limiting factor to productivity and reliability. Engineers were spending excessive time searching for service ownership details, deployment instructions, operational dashboards, and documentation scattered across multiple tools and repositories. This fragmentation undermined the DevOps goal of shared ownership and fast feedback loops. Rather than attempting to standardize behavior through policy alone, Spotify invested in reducing friction by design.
This strategic decision led to the creation of Backstage, an internal developer platform designed to serve as a single source of truth for the organization’s software ecosystem. Backstage consolidated critical information such as service catalogs, ownership metadata, deployment pipelines, documentation, operational metrics, and dependency mappings into a unified interface. By making this information easily accessible, Spotify enabled developers to understand, deploy, and operate services with greater confidence and autonomy. This approach reinforced core DevOps principles by embedding operational awareness directly into the developer workflow.
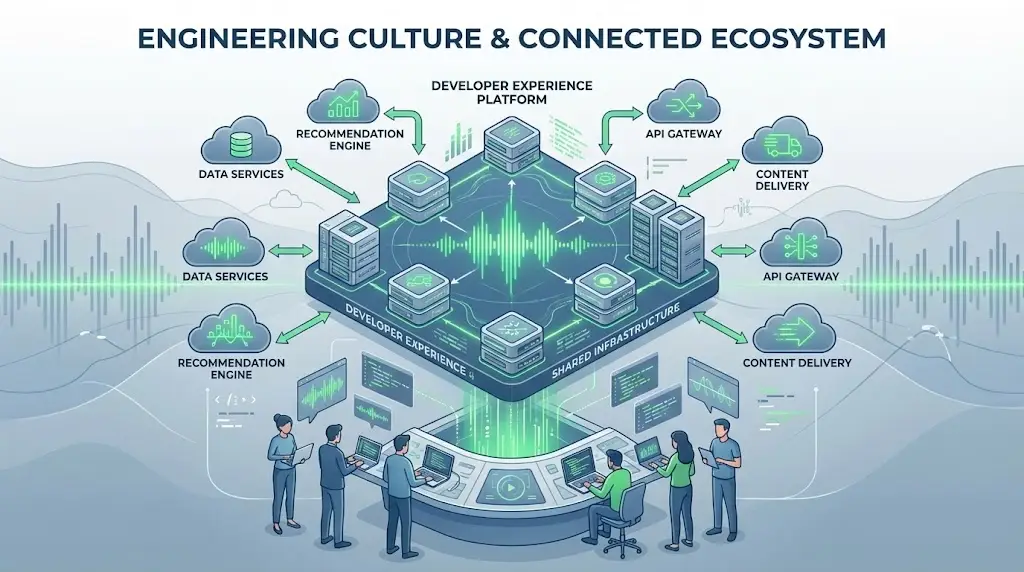
Backstage also played a critical role in standardizing best practices without sacrificing team independence. Spotify introduced service templates that embedded security, compliance, and deployment standards at the point of creation. Instead of enforcing governance through manual reviews or centralized approvals, guardrails were implemented through automation. This allowed teams to move quickly while remaining aligned with organizational expectations. Governance became an enabling function rather than a bottleneck, supporting both speed and consistency across the engineering organization.
Over time, Backstage evolved beyond a tooling solution into a foundational element of Spotify’s engineering culture. It improved onboarding efficiency, reduced operational risk, and strengthened accountability by clearly defining service ownership. Recognizing its broader value, Spotify later open sourced Backstage, allowing other enterprises to adopt and adapt the platform to their own DevOps initiatives. This move further cemented Spotify’s influence on modern DevOps practices beyond its own organization.
Spotify’s experience underscores the importance of developer experience as a first-class concern in DevOps strategy. At enterprise scale, productivity losses caused by system complexity can be as damaging as outages or performance issues. By investing in a platform that supports engineers and simplifies interactions with complex systems, Spotify ensured that its DevOps practices could scale sustainably alongside the organization. The result was not only faster delivery, but a more resilient and adaptable engineering culture capable of supporting long-term growth.
Target and Enterprise-Wide DevOps Enablement
Many DevOps Case Studies at enterprise scale show that cultural change is just as critical as tooling and automation.
Target’s transformation appears in many DevOps Case Studies focused on enterprise cultural change. Target’s DevOps transformation illustrates how large, established enterprises can modernize their technology practices without discarding the foundations that support their core business. With decades of legacy systems, deeply embedded operational processes, and a vast physical retail footprint across the United States, Target faced challenges that extended far beyond infrastructure modernization.
The organization needed to support both digital innovation and in-store operations, often under tight timelines and seasonal demand.Cultural inertia, siloed organizational structures, and traditional release governance models limited the company’s ability to respond quickly to evolving customer expectations and competitive pressure from digitally native retailers.
Recognizing that DevOps could not be introduced through tools or mandates alone, Target adopted a deliberate and education-driven approach to transformation. Instead of enforcing new practices from the top down, the company invested in experiential learning designed to change how teams worked on a daily basis. This strategy materialized through the creation of DevOps Dojos, immersive environments where cross-functional product teams temporarily stepped away from their routine delivery cycles to rethink how they built, tested, deployed, and operated software. These Dojos functioned as both training grounds and transformation catalysts, allowing teams to apply DevOps principles in real-world scenarios rather than theoretical exercises.
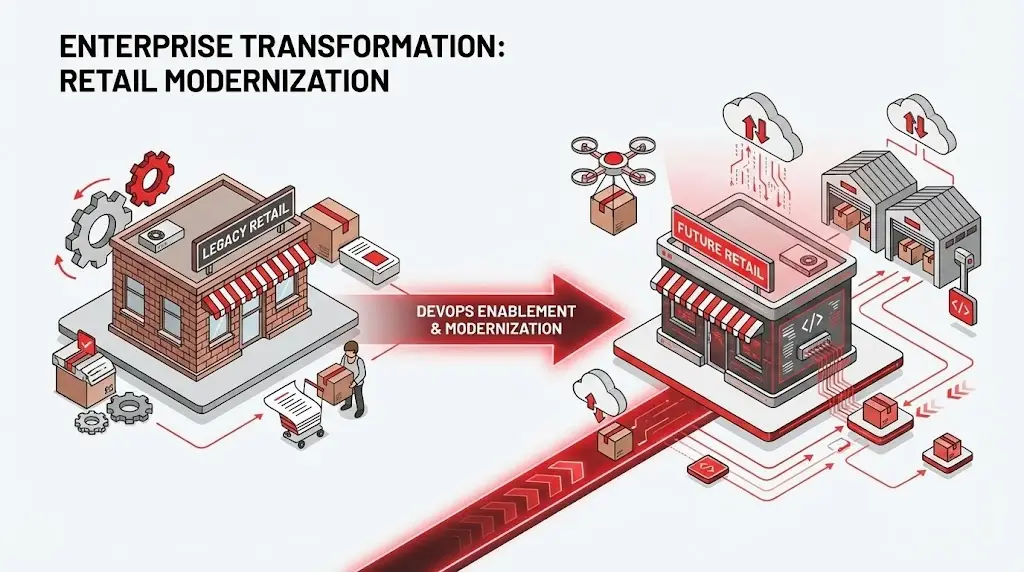
Within the Dojo environment, teams learned to implement continuous integration pipelines, automated testing frameworks, infrastructure automation, and production monitoring while working on actual business applications. Developers, operations specialists, and quality engineers collaborated closely, eliminating traditional handoffs and fostering shared accountability for outcomes. This hands-on model accelerated skill development and helped teams internalize DevOps concepts through practice rather than instruction. Importantly, the Dojos created a safe space for experimentation, enabling teams to identify inefficiencies, challenge long-standing assumptions, and learn from failures without fear of negative repercussions.
Executive leadership played a critical role in sustaining these changes. Target aligned performance metrics and incentives with DevOps outcomes such as deployment frequency, system stability, and customer impact rather than adherence to rigid processes. This alignment signaled that leadership valued learning, adaptability, and results over procedural compliance. As teams returned from the Dojo experience, they carried new ways of working back into the broader organization, gradually influencing adjacent teams and driving organic adoption of DevOps practices.
As DevOps principles spread across Target’s technology organization, the company saw measurable improvements. Release cycles shortened, system reliability increased, and teams gained greater autonomy over their services. Automation replaced manual approvals and repetitive tasks, reducing bottlenecks and human error. Ownership shifted closer to the teams building the software, enabling faster decision-making and more responsive incident management.
Target’s journey demonstrates that DevOps adoption in large enterprises requires more than technical modernization. It demands structured enablement, sustained leadership commitment, and long-term investment in people and culture. Tools and platforms can accelerate progress, but without a deliberate strategy to reshape how teams learn, collaborate, and take ownership, meaningful transformation remains out of reach.
Capital One and DevOps in a Regulated Environment
DevOps Case Studies in regulated industries provide valuable insight into balancing speed, security, and compliance.
Capital One is a defining example in DevOps Case Studies within regulated industries. Capital One’s DevOps transformation directly challenges the long-standing assumption that heavily regulated industries must choose between speed and safety. As one of the largest financial institutions in the United States, Capital One operates under strict regulatory oversight, with extensive requirements related to security, data privacy, compliance, and risk management. Historically, these constraints led many financial organizations to adopt cautious delivery models characterized by lengthy approval cycles, manual controls, and limited deployment frequency. Capital One recognized that this approach was increasingly incompatible with modern customer expectations and the pace of digital competition.
Rather than viewing regulation as an obstacle to DevOps, Capital One reframed governance as an engineering problem. The organization made a strategic decision to automate compliance instead of relying on human-driven processes. Security controls, regulatory requirements, and infrastructure standards were codified and embedded directly into continuous integration and continuous delivery pipelines. This approach ensured that every code change was evaluated against predefined policies automatically, reducing variability and eliminating the delays associated with manual reviews. As a result, teams were able to release software more frequently while maintaining a high level of regulatory assurance.
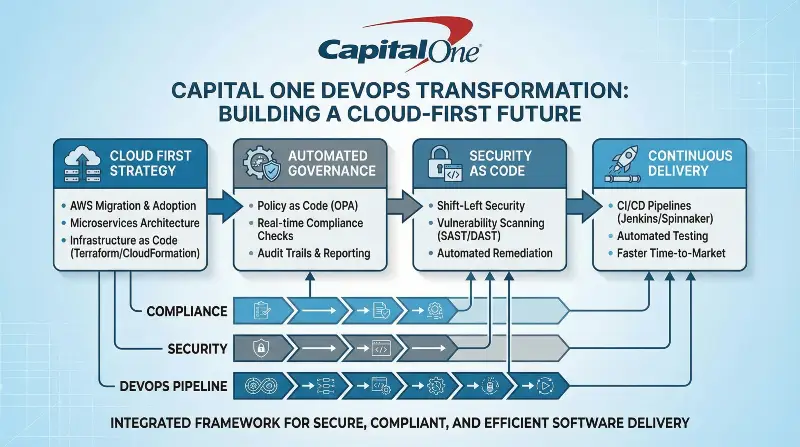
Capital One’s cloud-first strategy was central to this transformation. The company committed to migrating the majority of its workloads to the cloud, enabling greater consistency, scalability, and automation across environments. Rather than starting with low-risk systems, Capital One deliberately prioritized complex and mission-critical applications early in the migration process. This decision accelerated organizational learning by forcing teams to confront architectural challenges, security considerations, and operational constraints head-on. The insights gained from these early efforts informed standardized patterns and reusable frameworks that simplified subsequent migrations.
Education and workforce enablement played a critical role in sustaining DevOps adoption. Capital One invested heavily in training engineers across cloud-native architecture, security automation, infrastructure as code, and modern DevOps tooling. This emphasis on skill development reduced resistance to change and helped engineers understand how automated governance could enhance, rather than restrict, their ability to deliver value. By equipping teams with both technical knowledge and clear operating principles, Capital One fostered a culture of shared responsibility for security, reliability, and delivery outcomes.
Organizationally, Capital One aligned its DevOps initiatives with broader business objectives. Teams were encouraged to think in terms of product ownership rather than project delivery, strengthening accountability for long-term system health. Metrics shifted away from purely procedural compliance toward outcomes such as deployment reliability, recovery time, and customer impact. This alignment reinforced the idea that security, compliance, and speed were complementary rather than competing goals.
Capital One’s experience demonstrates that DevOps can simultaneously enhance agility and control when compliance is embedded into automated workflows. By replacing manual governance with engineered guardrails, the organization achieved faster release cycles, improved operational resilience, and a stronger security posture. This case provides a compelling model for other regulated enterprises seeking to modernize delivery practices without compromising trust or regulatory obligations.
Etsy and the Role of Blameless Culture in DevOps Maturity
Some of the most influential DevOps Case Studies emphasize learning culture, experimentation, and psychological safety.
Etsy’s approach is often highlighted in DevOps Case Studies centered on learning culture and continuous delivery. Etsy represents one of the earliest and most influential examples of DevOps transformation driven primarily by cultural change rather than large-scale tooling or platform overhauls. As a global online marketplace facilitating millions of transactions between independent sellers and buyers, Etsy faced constant pressure to deliver new features, improve performance, and maintain availability. The organization recognized early that traditional release processes, characterized by infrequent deployments and high-risk changes, were incompatible with its need for rapid iteration and customer responsiveness.
To address this challenge, Etsy adopted continuous deployment as a core operating principle. Instead of bundling changes into large releases, engineers deployed small, incremental updates frequently throughout the day. This shift significantly reduced the risk associated with each deployment, as smaller changes were easier to understand, test, and roll back if necessary. Frequent releases also shortened feedback loops, allowing teams to identify issues quickly and respond before problems escalated into major incidents. Continuous deployment became not only a technical practice, but a strategic enabler of faster learning and innovation.
Supporting this delivery model required deep investment in monitoring and observability. Etsy treated visibility into system behavior as a first-class concern, ensuring that engineers had access to real-time metrics, logs, and alerts. Rather than relying on centralized operations teams to detect issues, individual teams were empowered to monitor the health of their services directly. This approach strengthened accountability and improved incident response by ensuring that those closest to the code also had the clearest insight into its behavior in production.
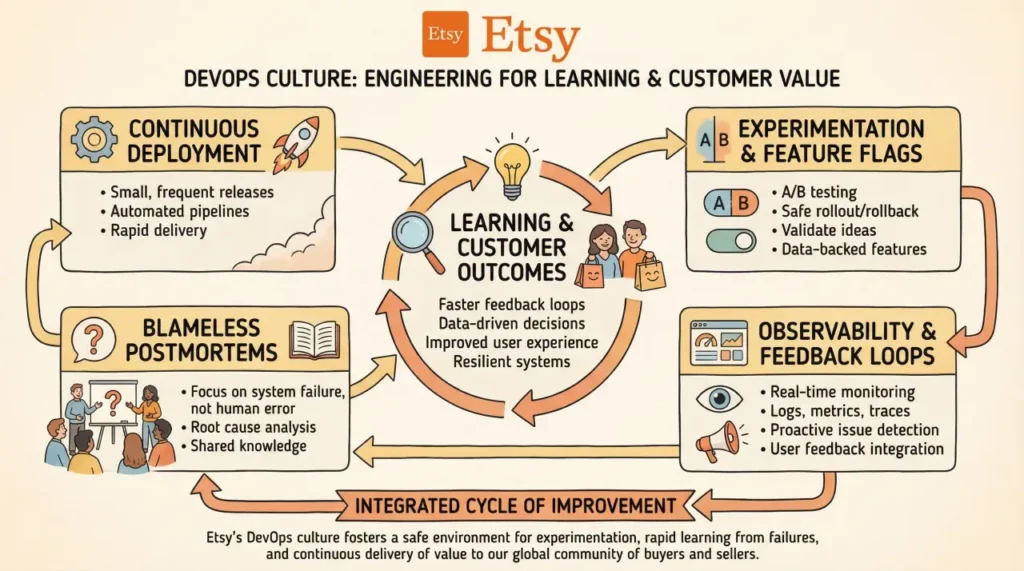
A defining element of Etsy’s DevOps culture was its commitment to blameless postmortems. When incidents occurred, the focus shifted away from identifying individual mistakes and toward understanding systemic contributors such as unclear processes, missing safeguards, or inadequate tooling. This practice fostered transparency and trust, encouraging engineers to share information openly and participate actively in improvement efforts. By removing fear from failure analysis, Etsy created an environment where learning could occur continuously and collectively.
Etsy further integrated DevOps practices with business experimentation through the use of feature flags and controlled experiments. These mechanisms allowed teams to test new functionality with limited audiences, measure real-world impact, and make data-driven decisions before full rollouts. Technical changes were closely aligned with customer outcomes, reinforcing the connection between engineering work and business value. This integration ensured that DevOps was not isolated within engineering, but directly supported product strategy and customer experience.
Etsy’s experience demonstrates that DevOps maturity depends as much on psychological safety and organizational trust as it does on technical capability. By prioritizing learning over blame and enabling engineers to operate with autonomy and visibility, Etsy established a sustainable model for rapid delivery. Organizations that cultivate similar environments are better positioned to innovate continuously while maintaining system stability and long-term resilience.
Additional DevOps Case Studies Context:
DevOps Case Studies are often used by enterprise leaders to understand how large organizations implement DevOps at scale. These DevOps Case Studies provide insight into real-world challenges involving legacy systems, regulatory requirements, distributed teams, and platform complexity. By studying DevOps Case Studies across different industries, organizations can identify patterns that apply to their own DevOps transformation journeys. Well-documented DevOps Case Studies also help decision-makers evaluate tooling, culture, governance, and organizational structure before investing in DevOps initiatives.
Frequently Asked Questions About DevOps Case Studies
What are DevOps case studies?
DevOps case studies are real-world examples that explain how organizations adopt DevOps practices to improve software delivery speed, system reliability, collaboration between teams, and overall operational efficiency.
Why are DevOps case studies important for enterprises?
DevOps case studies are important because they show how DevOps works in complex enterprise environments that include legacy systems, regulatory constraints, large engineering teams, and global infrastructure.
Which companies have the best DevOps case studies?
Some of the most widely referenced DevOps case studies come from companies such as Netflix, Spotify, Target, Capital One, and Etsy, each demonstrating different approaches to DevOps at enterprise scale.
What can organizations learn from DevOps case studies?
By studying DevOps case studies, organizations can learn how to implement continuous delivery, improve system resilience, scale developer productivity, and align culture with automation and governance.
Are DevOps case studies useful for regulated industries?
Yes, DevOps case studies are especially valuable for regulated industries because they show how organizations balance speed, security, compliance, and risk management through automation and platform engineering.
How do DevOps case studies support DevOps transformation?
DevOps case studies support DevOps transformation by providing proven patterns, common pitfalls, and practical lessons that organizations can apply when modernizing their software delivery processes.
Who should read DevOps case studies?
DevOps case studies are useful for CTOs, CIOs, engineering leaders, DevOps practitioners, architects, and business leaders involved in technology transformation initiatives.
Key Takeaways for Enterprise DevOps Leaders
Together, these DevOps Case Studies demonstrate how organizations can balance speed, reliability, and governance through disciplined DevOps adoption. These case studies reveal that successful DevOps transformations are not defined by industry, company size, or technology stack, but by a shared commitment to long-term change. Automation creates speed, but culture sustains it. Platforms reduce complexity, but education ensures adoption. Above all, DevOps succeeds when organizations stop treating delivery, reliability, and learning as isolated responsibilities and instead recognize them as collective obligations that shape business performance.
Netflix, Spotify, Target, Capital One, and Etsy each pursued DevOps through different strategies and constraints, yet all arrived at the same conclusion: meaningful transformation cannot be rushed. Each organization invested deliberately in people, platforms, and leadership alignment, choosing capability building over short-term efficiency gains. Their success demonstrates that DevOps maturity is not achieved through isolated tooling decisions or temporary initiatives, but through sustained commitment at every level of the organization. Taken together, these DevOps Case Studies provide a practical blueprint for organizations pursuing sustainable DevOps maturity.
For enterprise leaders evaluating DevOps consulting engagements or internal transformation programs, these stories offer both inspiration and direction. They show what is possible when organizations move beyond surface-level adoption and confront the deeper cultural, architectural, and operational changes required to compete in a digital-first economy. They also serve as a reminder that DevOps is not an engineering trend to be delegated, but a strategic decision that shapes how an organization learns, adapts, and delivers value over time.
DevOps is not a destination that can be reached and declared complete. It is an ongoing discipline that demands reflection, investment, and leadership courage. Organizations that embrace this reality position themselves not only to deliver software more effectively, but to build resilient systems, empowered teams, and enduring competitive advantage. The question is no longer whether DevOps is necessary, but whether the organization is willing to commit fully to the journey it requires. Check companies at Devopscompanies.org
Comments